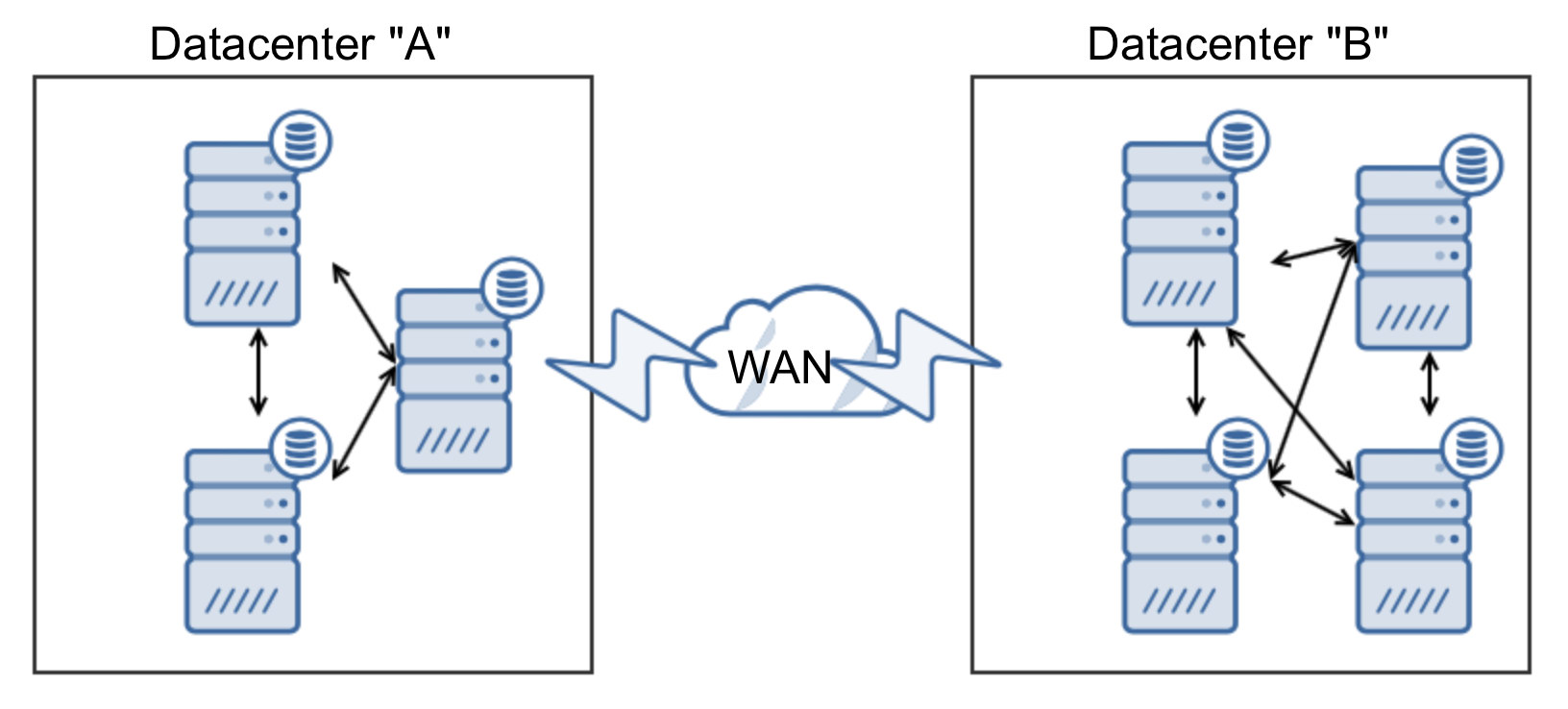
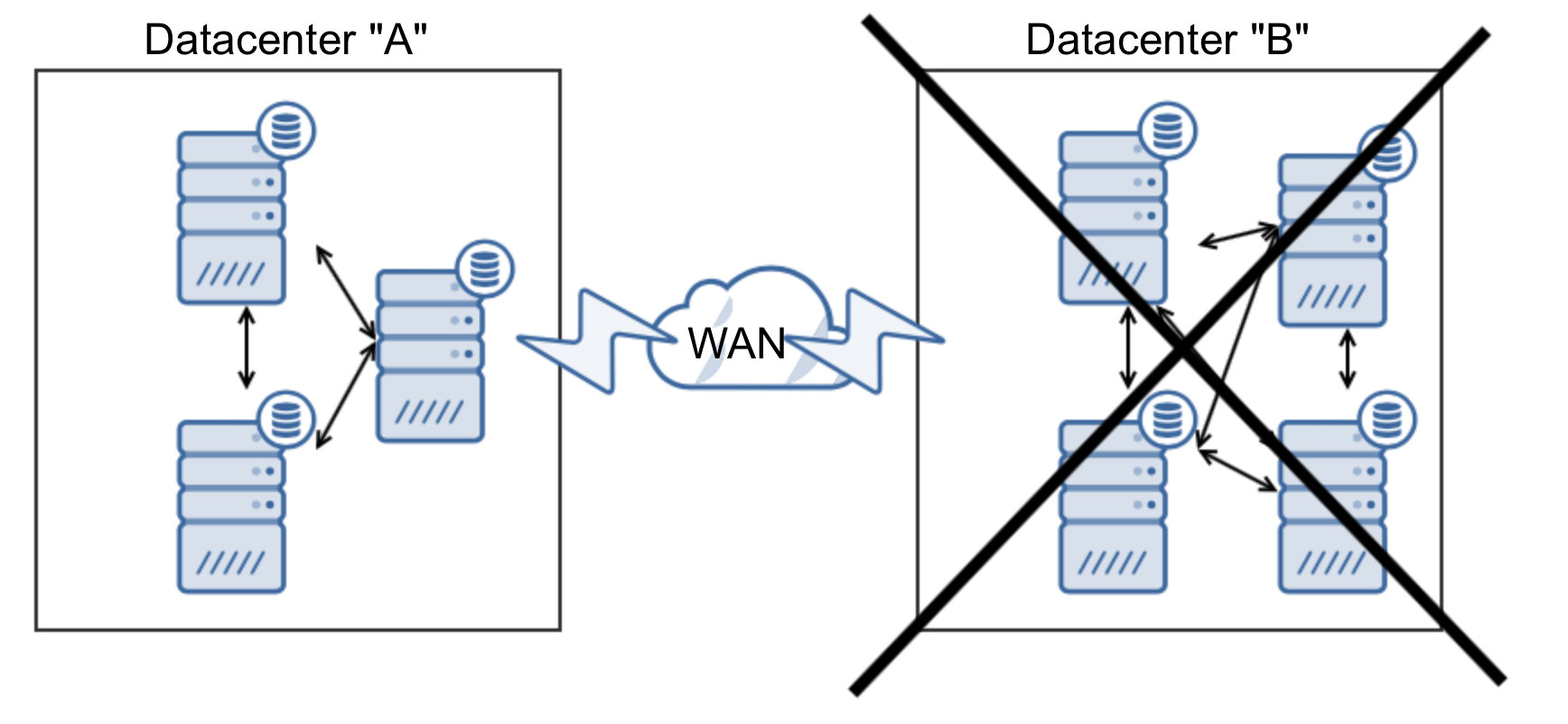
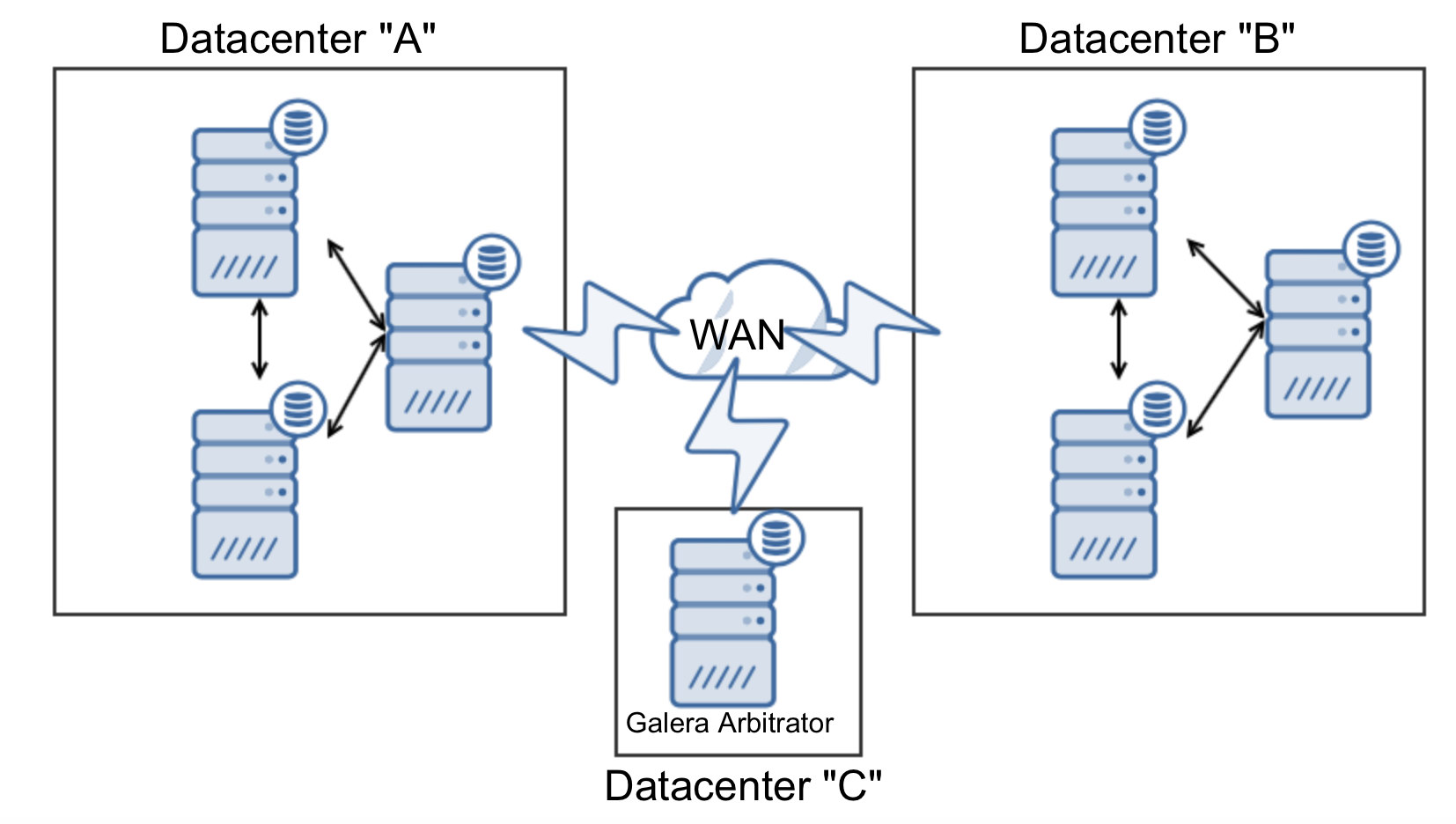
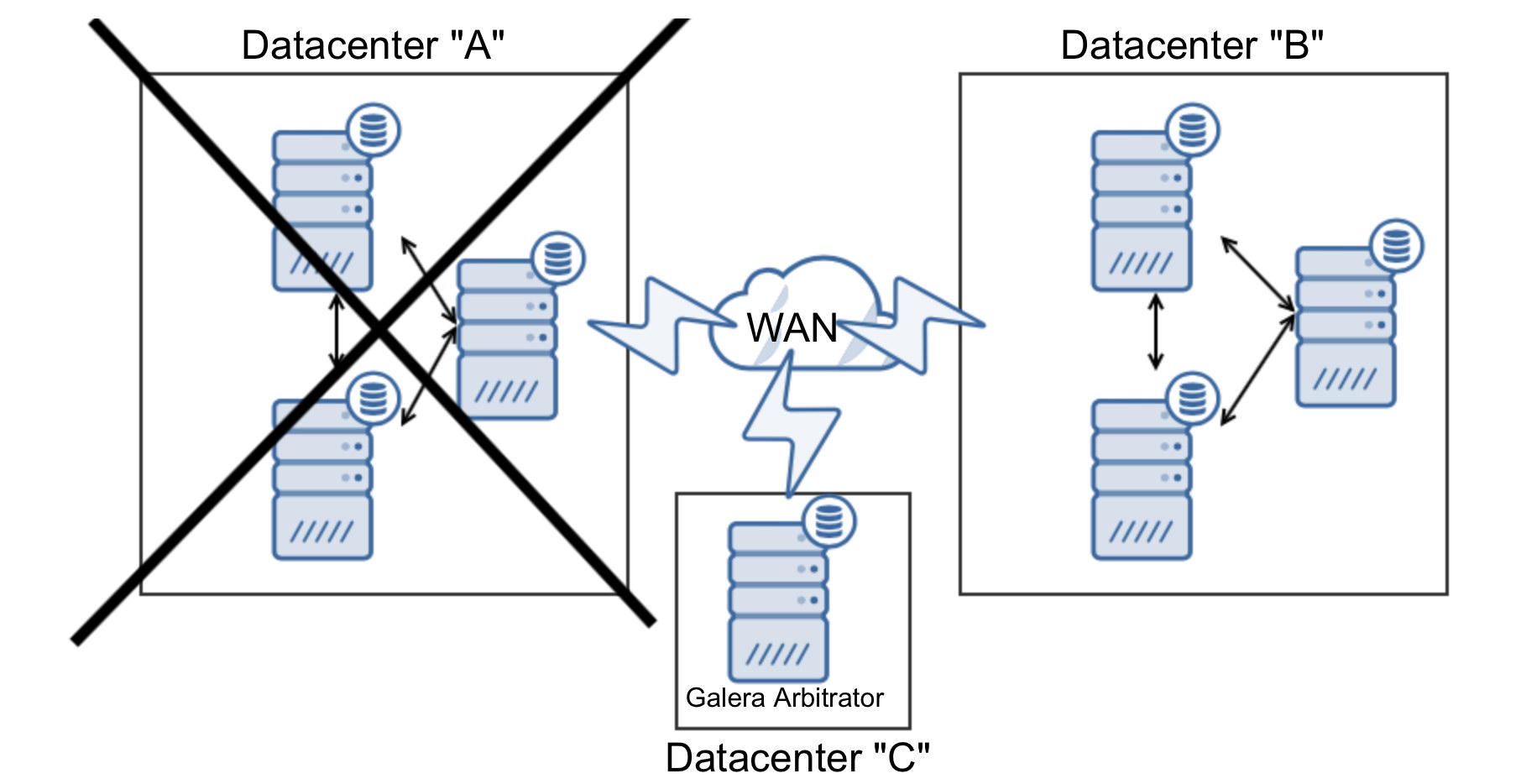
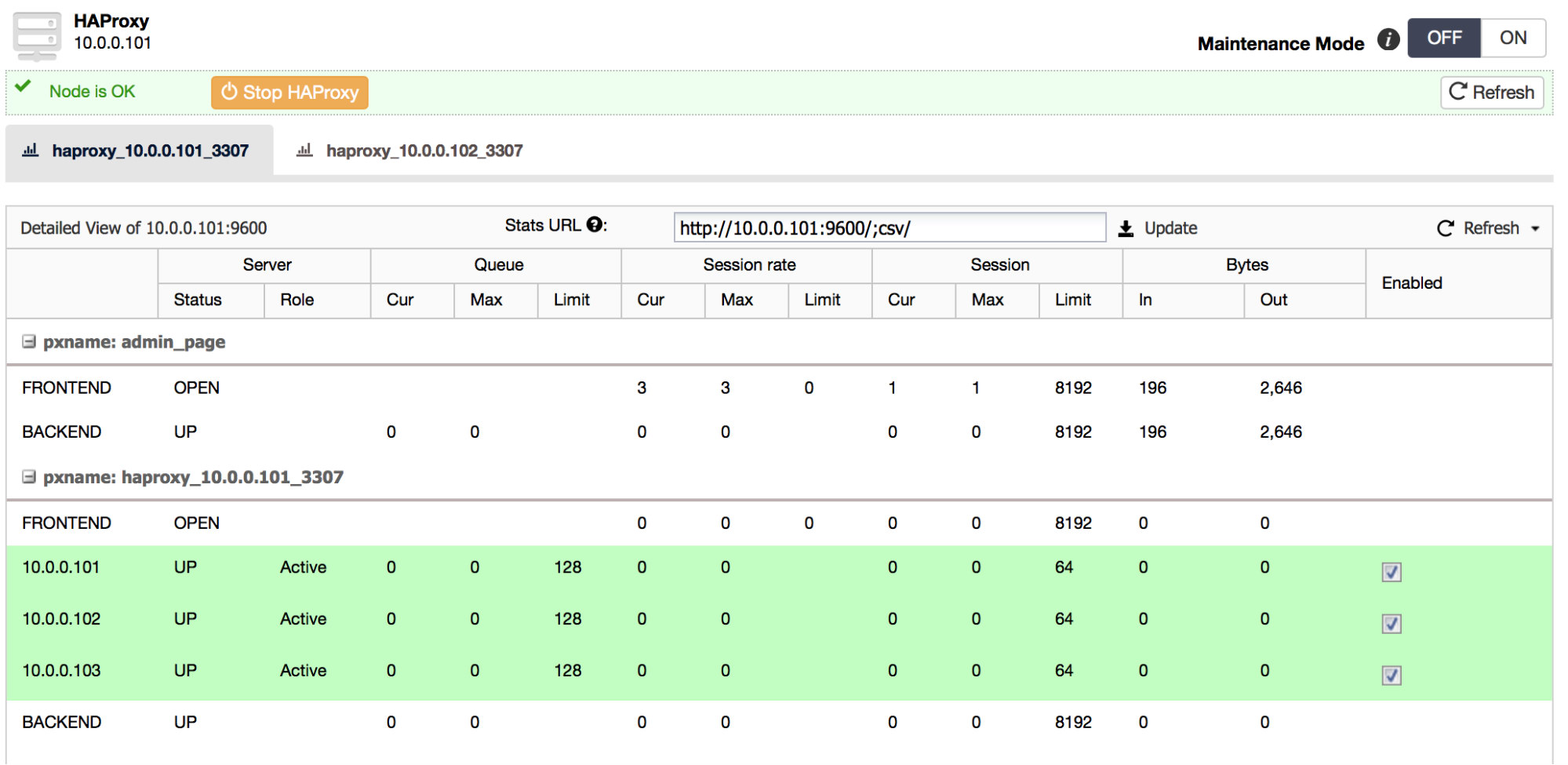
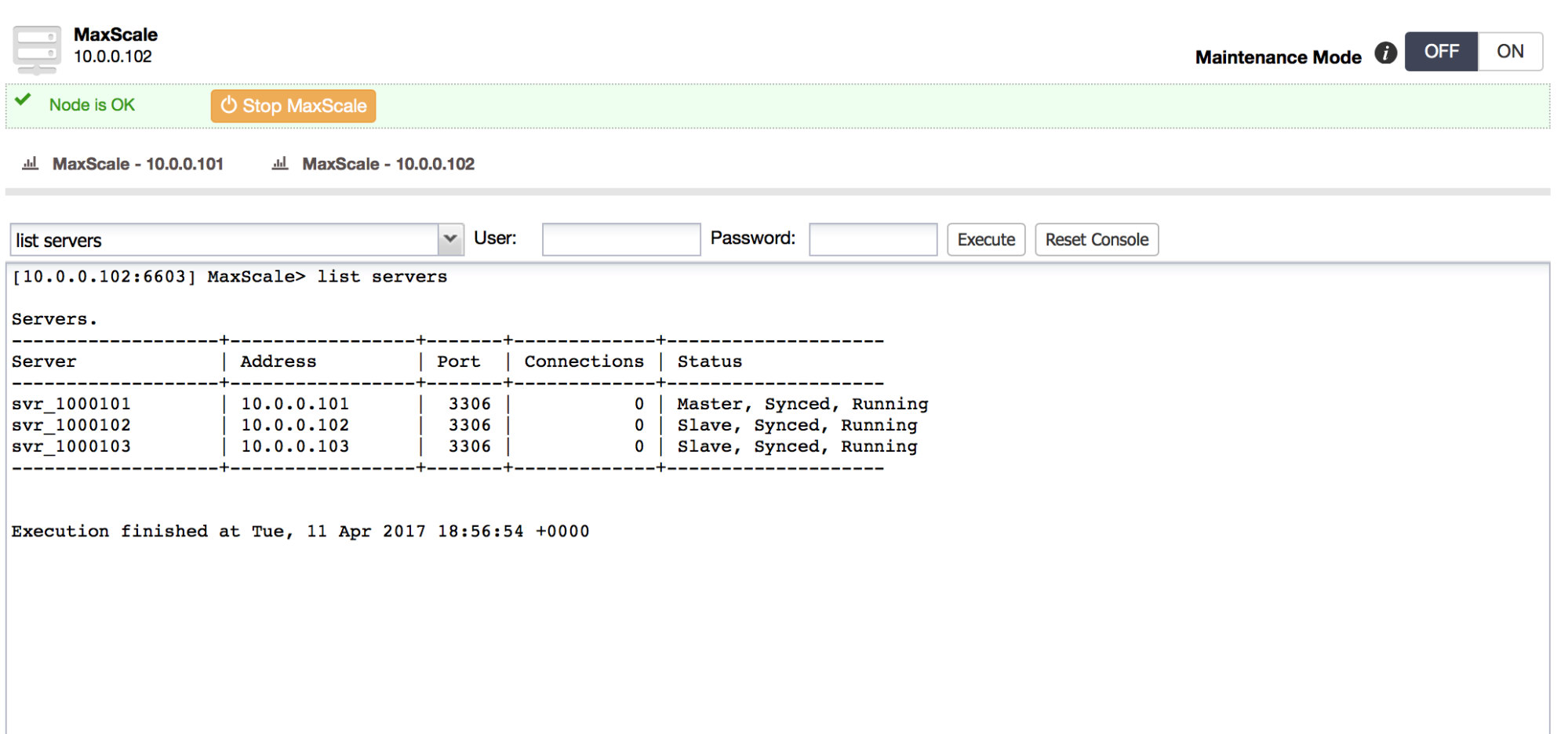
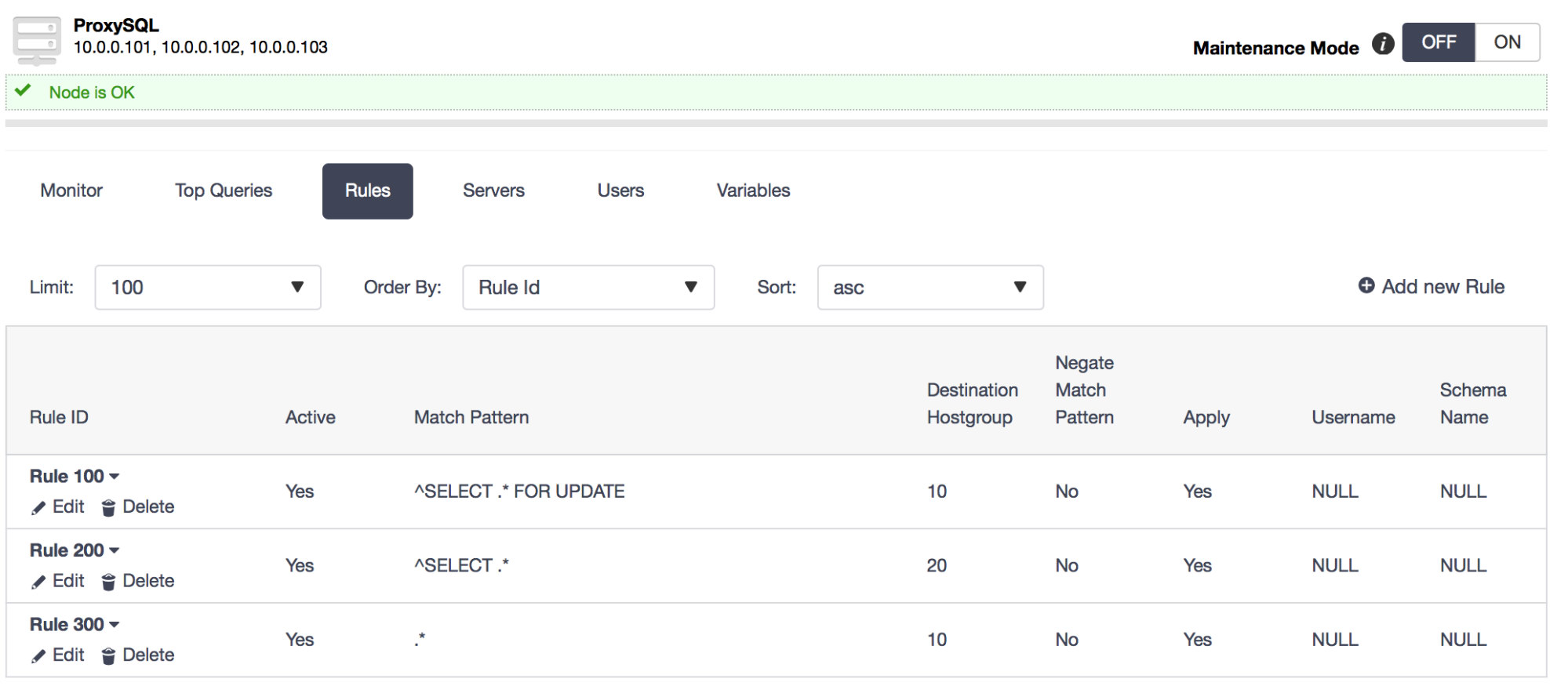
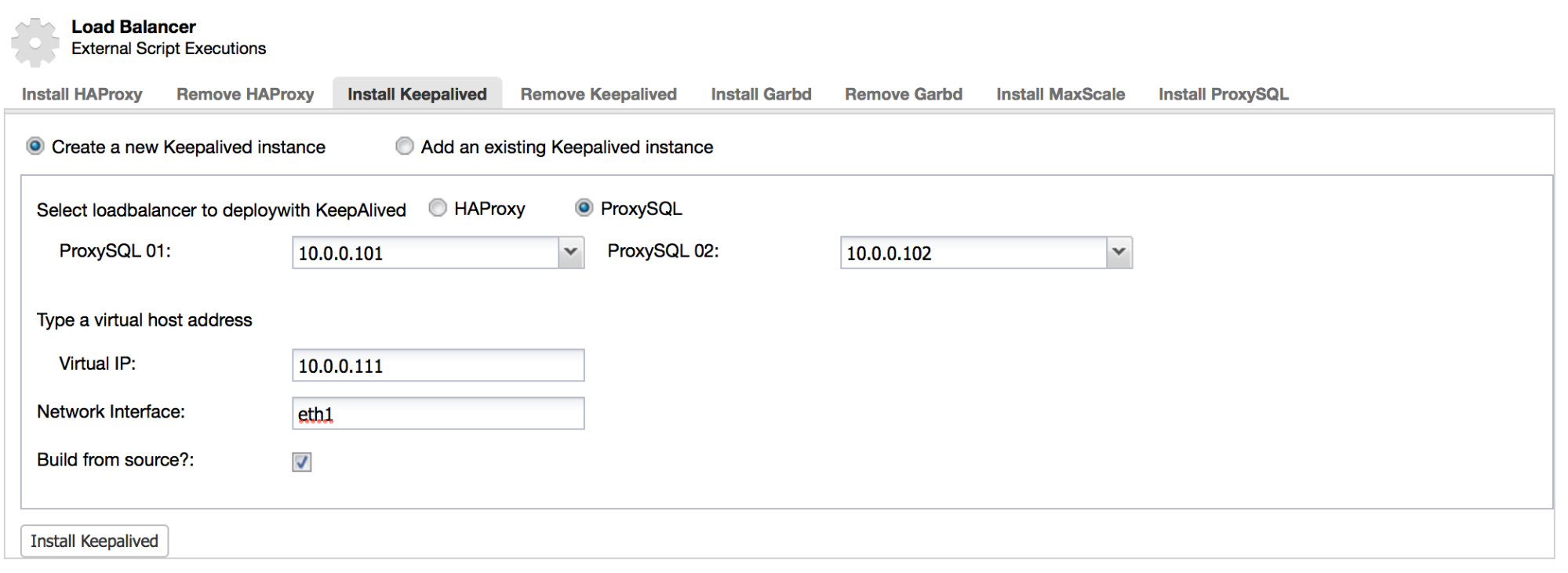
Since MongoDB is the favored database for many developers, it comes to no surprise that the community support is excellent. You can quickly find answers to most of your problems on knowledge sites like Stack Overflow, but the community also creates many tools, scripts and frameworks around MongoDB.
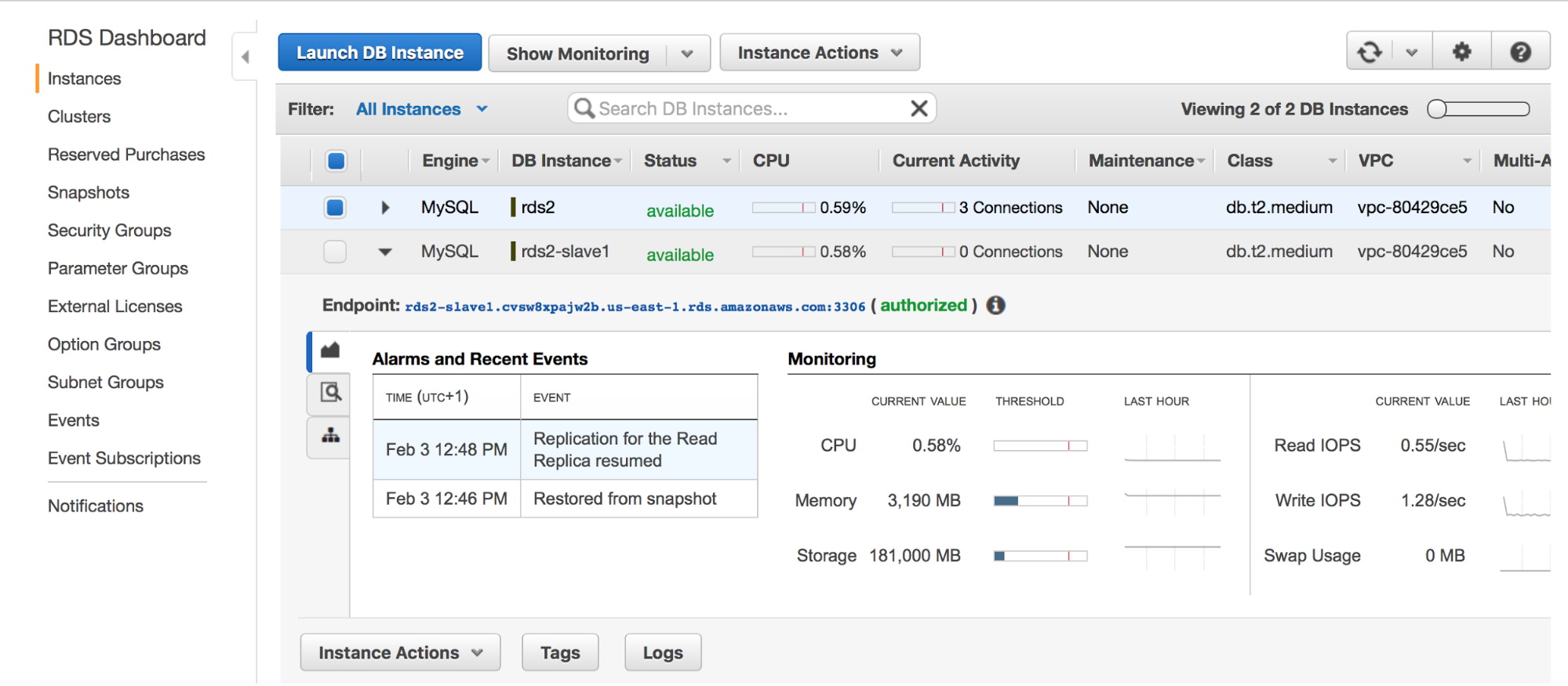
ClusterControl is part of the community tools that allow you to deploy, monitor, manage and scale any MongoDB topology. ClusterControl is designed around the database lifecycle, but naturally it can’t cover all aspects of a development cycle. This blog post will cover a selection of community tools that can be used to complement ClusterControl in managing a development cycle.
Schema management
The pain of schema changes in conventional RDBMS was one of the drivers behind the creation of MongoDB: we all suffered from painfully slow or failed schema migrations. Therefore MongoDB has been developed with a schemaless document design. This allows you to change your schema whenever you like, without the database holding you back.
Schema changes are generally made whenever there is application development. Adding new features to existing modules, or creating new modules may involve the creation of another version of your schema. Also schema and performance optimizations may create new versions of your schemas.

Even though many people will say it’s brilliant not being held back by the database, it also brings a couple of issues as well: since old data is not migrated to the new schema design, your application should be able to cope with every schema version you have in your database. Alternatively you could update all (old) data with the newer schema right after you have deployed the application.
The tools discussed in this section will all be very helpful in solving these schema issues.
Meteor2 collection
The Meteor2 collection module will ensure that from both client and server side, the schema will be validated. This will ensure that all data gets written according to the defined schema. The module will only be reactive, so whenever data does not get written according to the schema, a warning will be returned.
Mongoose
Mongoose is Node.js middleware for schema modelling and validation. The schema definition is placed inside your Node.js application, and this will allow Mongoose to act as an ORM. Mongoose will not migrate existing data into the new schema definition.
MongoDB Schema
So far we only have spoken about schema changes, so it is time to introduce MongoDB Schema. MongoDB Schema is a schema analyzer that will take a (random) sample of your data and output the schema for the sampled data. This doesn’t necessarily mean it will be 100% accurate on its schema estimation though.

With this tool you could regularly check your data against your schema and detect important or unintentional changes in your schema.
Backups
ClusterControl supports two implementations for backing up MongoDB: mongodump and Percona Consistent Backup. Still, some less regular used functionalities, like partial/incremental backups and streaming backups to other clusters, will not be available out of the box.
MongoDB Backup
MongoDB Backup is a NodeJS logical backup solution that offers similar functionality as mongodump. In addition to this, it can also stream backups over the network, making it useful for transporting a collection from one MongoDB instance to another.
Another useful feature is that it has been written in NodeJS. This means it will be very easy to integrate in a Hubot chatbot, and automate the collection transfers. Don’t be afraid if your company isn’t using Hubot as a chatbot: it can also function as either a webhook or be controlled via the CLI.
Mongob
Mongob is another logical backup solution, but in this case it has been written in Python and is only available as a CLI tool. Just like MongoDB Backup, it is able to transfer databases and collections between MongoDB instances, but in addition to that, it can also limit the transfer rate.
Another useful feature of Mongob is that it will be able to create incremental backups. This is good if you wish to have more compact backups, but also if you need to perform a point in time recovery.
MongoRocks Strata
MongoRocks Strata is the backup tool for the MongoRocks storage engine. Percona Server for MongoDB includes the MongoRocks storage engine, however it lacks the Strata backup tool for making file level backups. In principle mongodump and Percona Consistent Backup are able to make reliable backups, but as they are logical dumps the recovery time will be long.
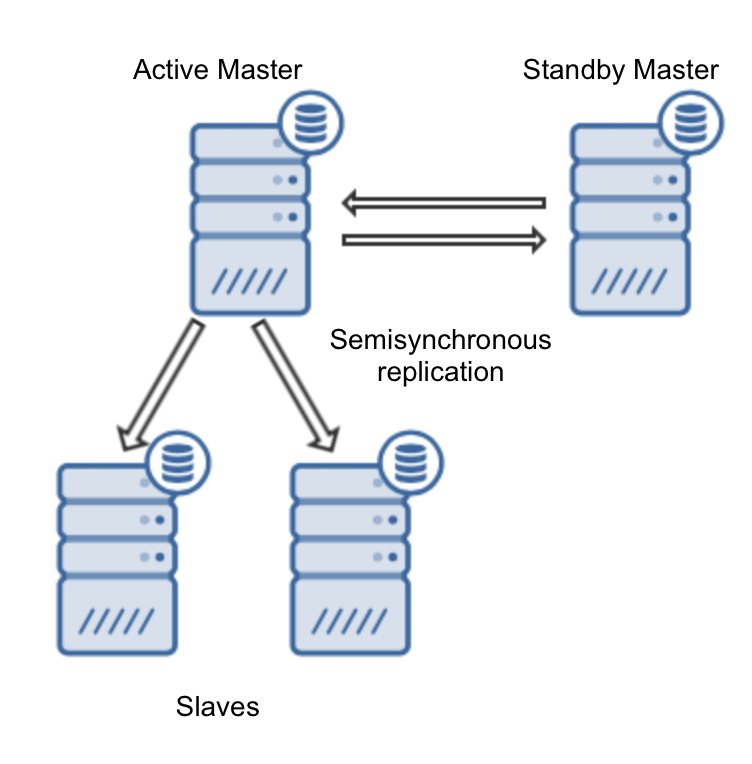
MongoRocks is a storage engine that relies on a LSM tree architecture. This basically means it is an append only storage. To be able to do this, it operates with buckets of data: older data will be stored in larger (archive) buckets, recent data will be stored in smaller (recent) buckets and all new incoming data will be written into a special memory bucket. Every time a compaction is done, data will trickle down from the memory bucket to the recent buckets, and recently changed data back to the archive bucket.

To make a backup of all buckets, Strata instructs MongoDB to flush the memory bucket to disk, and then it copies all buckets of data on file level. This will create a consistent backup of all available data. It will also be possible to instruct Strata to only copy the recent buckets and effectively take an incremental backup.
Another good point of Strata is that it provides the mongoq binary, that allows you to query the backups directly. This means there is no need to restore the backup to a MongoDB instance, before being able to query it. You would be able to leverage this functionality to ship your production data offline to your analytics system!
MongoDB GUIs
WIthin ClusterControl we allow querying the MongoDB databases and collections via advisors. These advisors can be developed in the ClusterControl Developer Studio interface. We don’t feature a direct interface with the databases, so to make changes to your data you will either need to log into the MongoDB shell, or have a tool that allows you to makes these changes.
PHPMoAdmin
PHPMoAdmin is the MongoDB equivalent of PHPMyAdmin. It features similar functionality as PHPMyAdmin: data and admin management. The tool will allow you to perform CRUD operations in both JSON and PHP syntax on all databases and collections. Next to all that, it also features an import/export functionality of your current data selection.

Mongo-Express
If you seek a versatile data browser, Mongo-Express is a tool you definitely need to check out. Not only does it allow similar operations as PHPMoAdmin, it also is able to display images and videos inline. It even supports fetching large objects from GridFS buckets.
Robomongo
The tool that goes one step further is Robomongo. Being a crowd funded tool, the feature list is huge. It is able to perform all the same operations as Mongo-Express, but in addition to this also allows user, role and collection management. For connections it supports direct MongoDB connections, but also supports replicaSet topologies and MongoDB Atlas instances.

Conclusion
With this selection of free community tools, we hope we have given you a good overview how to manage MongoDB data next to ClusterControl.
Happy clustering!